There are 2 tools to utilize search engine:
– the Harvester using the terminal
– Maltego
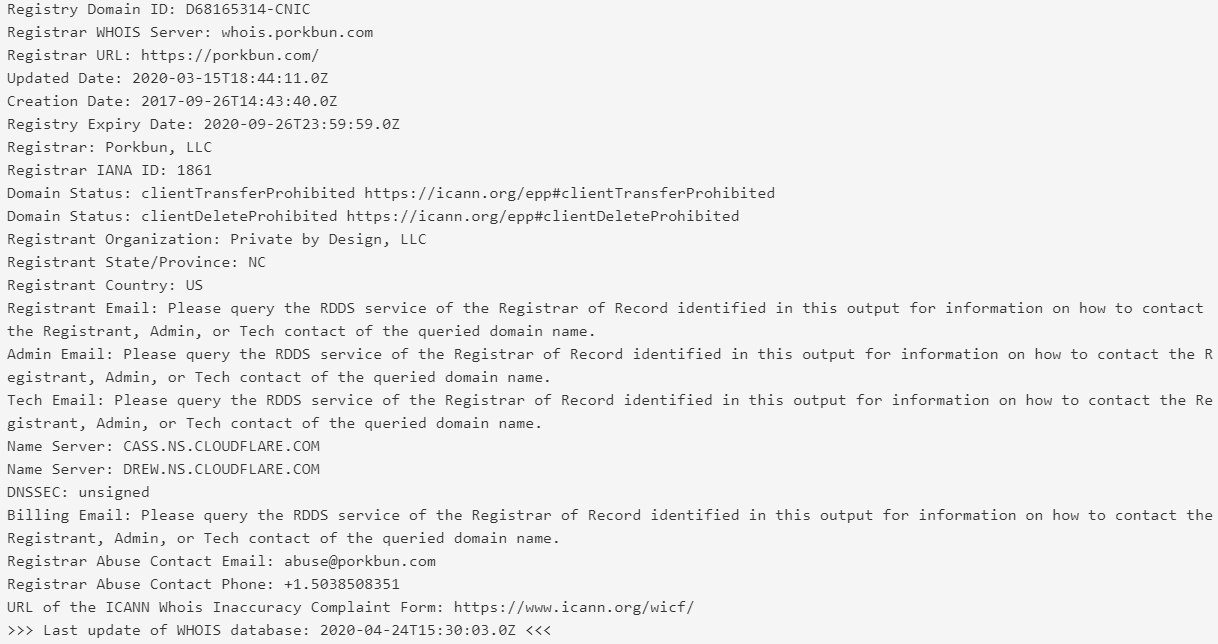
Using the Harvester through the terminal will only give you information that is leaked or available on the search engine. To use this tool is very easy, open the terminal on your kali linux, and type theharvester or theHarvester depends on your version of kali linux. -d is the domain that you want to search -l is the amount of data you want your terminal to show -b is the search engine you want to use.
For example: theHarvester -d facebook.com -l 100 -b bing
When you enter the command, it will show you the results it can find with a maximum amount of 100 results.
Another tool is using maltego. Maltego is an application that is available on kali linux. Before using this application, you must register yourself and log in to use the tools in maltego. After you log yourself in, you will see many tools that are available for you to use. But for finding data behind a website or a domain, you can just click new graph, and press what you want to find trace of, if you want to find information traces from a domain, you can choose domain, name the domain you want to find, and then click transform. Wait for a while until all the data are showed, it will be showed in the form of trees and branches. Something like this:
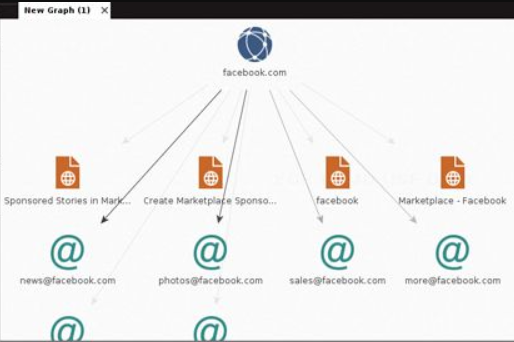
If you want to find a data about another person, you can! But you have to log in to your twitter first, after you are done with logging in to your twitter account, maltego will find the data related to the person you are searching for.
Utilizing Search Engines
Reply